Lecture notes
Introduction to linear regression
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./data/advertising.csv')
plt.scatter(x='TV', y='sales', data=df)
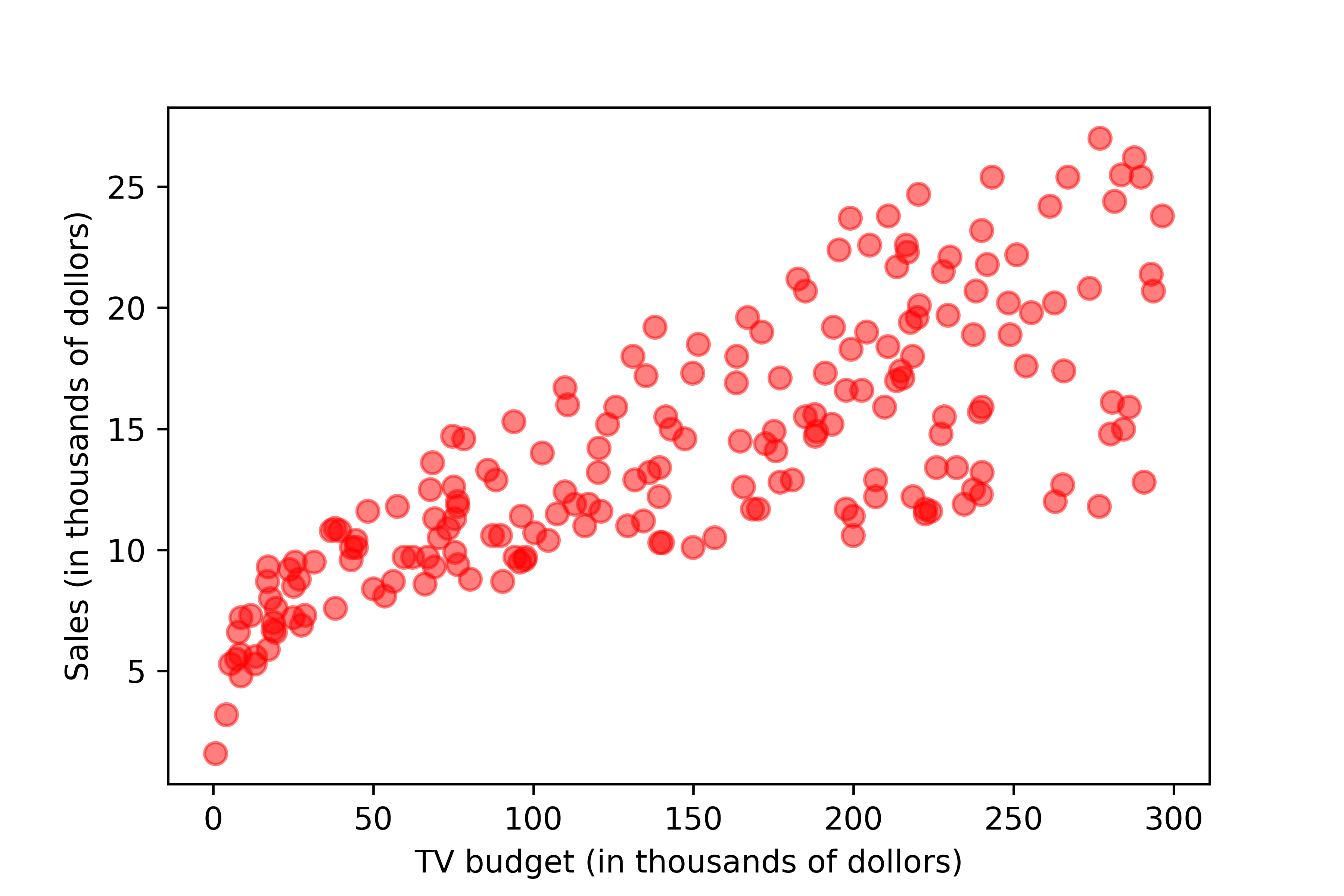
Questions that we may ask
Is there a relationship between advertising budget (TV, radio, and newspaper) and the sales?
If yes, how strong is the relationship?
Is the relationship linear?
How accurately can we estimate the effect of each channel on sales?
Given the budget, how accurately can we predict future sales?
Is there any synergy among the media?
Linear regression : Study the relationship between two or more variables.
Simple linear regression : The model takes the form
where
\(x\): a given input to the model
\(\epsilon\): the error term modeled as a normally-distributed random variable \(\epsilon \sim \text{N}(0, \sigma^2)\)
\(\beta_0 \text{ and } \beta_1\): unknown parameters in the model
Question: Is \(Y\) a random variable?
What is the expected value of \(Y\)?
What is the variance of \(Y\)?
What distribution does \(Y\) follow?
\(\beta_0\): the intercept, the expected value of \(Y\) when \(x=0\).
\(\beta_1\): the slope, the expected change of \(Y\) per unit change of \(x\).
Parameter estimation
The problem
What would be our “best” estimates of \(\beta_0\) and \(\beta_1\)? In other words, what it the model that fits the data the best?
Naturally, we may want to take a look at the “errors” that the model made in its responses (\(\hat{y}_i\)) when compared with the actual data (\(y_i\)) at each of the given input values \(x_i\).
In statistics, these “errors” are often called “residuals”, as they are the remaining variations in the data (\(y_i\)) that can not be explained by a statistical model.
Question: Can we use the sum of all the residuals as a metric to find the best model?
It is not a good idea, as the positive and negative residuals would cancel each other out.
Instead, we square the residuals before summing them up. The result is called the Residual Sum of Squares (RSS).
Ordinary Least Squares (OLS)
Given \(n\) pairs of data
We choose \(\beta_0\) and \(\beta_1\) such that the RSS is minimized.
This method is called Ordinary Least Squares (OLS).
To find the minimum of the function \(f(\beta_0, \beta_1)\), we take partial derivatives of the function w.r.t. \(\beta_0\) and \(\beta_1\), and set the derivatives to 0.
Then we can use linear algebra to solve for \(\beta_0\) and \(\beta_1\).
From Eq. (\(\ref{a}\))
From Eq. (\(\ref{b}\))
Now multiply both sides of Eq. (\(\ref{c}\)) by \(\sum x_i\), and multiply both sides of Eq. (\(\ref{d}\)) by \(n\), we have
Lastly, Subtract both sides of Eq. (\(\ref{e}\)) from Eq. (\(\ref{f}\)), we have
The intercept estimate \(\hat{\beta}_0\) can be obtained from Eq. (\(\ref{c}\))
where \(\bar{x}\) and \(\bar{y}\) are the sample means for \(x\) and \(y\) from the data.
OLS solution
Given \(n\) pairs of data \((x_1, y_1), (x_2, y_2), \cdots, (x_n, y_n)\), the Ordinary Least Squares solution is
Some intuition
OLS slope estimate
Roughly speaking, \(\hat{\beta}_1\) measures how much two variables \(x\) and \(y\) vary together, relative to the variability of the independent variable \(x\) itself.
Further resources
Assessing the accuracy of the parameter estimates
The slope estimator
From the OLS solution, we have
If we replace \(\beta\) with \(B\) (indicating it’s a random variable), and replace \(y\) with \(Y\), we can write the OLS slope estimator \(\hat{B}_1\) as
Below we show that the slope estimator \(\hat{B}_1\) follows a normal distribution with the following mean and variance.
To prove it we first show that \(\hat{B}_1\) is a linear combination of \(\hat{Y}_i\)’s.
Theorem
For \(n\) sample data \(x_1, x_2, \cdots, x_n\), the sum of all deviations from the sample mean \(\bar{x}\) is zero.
Proof:
Theorem
Any linear combination of independent normally distributed random variables also follows a normal distribution (see proof).
Since \(Y_i\)’s are normally-distributed and independent of each other, \(\hat{B}_1\), a linear combination of \(Y_i\)’s, follows a normal distribution.
Next, we show that the expected value of \(\hat{B}_1\) is \(\beta_1\).
When an estimator’s expected value equals the true value of the parameter being estimated, we say that the estimator is unbiased. From the above we show that the OLS slope parameter \(\hat{B}_1\) is an unbiased estimator for the slope parameter \(\beta_1\) in the simple linear regression model.
Then, we show that the variance of \(\hat{B}_1\) is \(\frac{\sigma^2}{\sum (x_i - \bar{x})^2}\).
Important
The OLS slope estimator
In practice, we do not know \(\sigma\), the true standard deviation of the error term \(\epsilon\) in the regression model. The best thing we can do is to estimate the variance from the data at hand.
The estimated standard deviation \(\hat{\sigma}\) is often called Residual Standard Error (RSE).
After we replace \(\sigma\) with \(\hat{\sigma}\), the variance of the slope estimator \(\hat{B}_1\) becomes
Similarly, the standard deviation of the slope estimator \(\hat{B}_1\), often called the Standard Error (SE) of the estimator, become
After replacing \(\sigma\) with \(\hat{\sigma}\), the standardized version of the slope estimator \(\hat{B}_1\) follows a t-distribution with degree of freedom of \(n-2\).
Confidence interval
We can construct a confidence interval (at confidence level \(1-\alpha\)) for the slope parameter \(\beta_1\).
Based on the above, we have the confidence interval (at confidence level \(1-\alpha\)) for the slope parameter \(\beta_1\) as
or simply
where \(\hat{\beta}_1\) is the OLS estimate of the slope parameter.
Hypothesis test
\(\text{H}_0\): There is no relationship between \(x\) and \(y\).
\(\text{H}_a\): There is some relationship between \(x\) and \(y\).
Mathematically, this corresponds to
We compute a t-statistic, given by
It measures the number of standard deviations that \(\hat{\beta}_1\) is away from 0.
If there really is no relationship between \(x\) and \(y\), the t-statistic will have a t-distribution with the degree of freedom of \(n-2\).
We reject the null hypothesis \(\text{H}_0\) if
or
Roughly speaking, a small p-value means it’s unlikely to observe such a relationship due to chance, if there really is no relationship.
Equivalently, we can also check if the confidence interval for \(\beta_1\) include 0. If it does, it means the relationship is not significant.
Assessing the accuracy of the model
Once we reject the null hypothesis \(\text{H}_0\) (i.e., stating that there is some relationship between \(x\) and \(y\)), we want to quantify the extent to which the model fits the data.
A natural thought is to use something that measures the “average amount of errors” that the model made. The Residual Standard Error (RSE) that we used previously is such an measure.
RSE provides an absolute measure of the model’s lack of fit.
In the advertising example sales ~ TV, the RSE is 3.26 (thousands of units).
It can be interpreted as the actual sales in each market deviates from the true regression line (the model prediction) by 3,260 units, on average.
One major limitation of using RSE as a measure of model accuracy is that it is not always clear what constitutes a “good” RSE. For example, is an average error of 3,260 units good?
\(R^2\) statistic
Compare with the RSE, a more common metric to assess the model accuracy is the \(R^2\) statistic (also called the coefficient of determination).
We define the following:
RSS (Residual Sum of Squares)
RSS measures the amount of variability in \(y\) that is left unexplained after performing the regression on \(x\).
TSS (Total Sum of Squares)
TSS measures the total amount of variability inherent in \(y\) before performing the regression on \(x\).
\(\text{TSS}-\text{RSS}\) measures the amount of variability in \(y\) that is explained by performing the regression on \(x\).
\(R^2\) measures the proportion of variability in \(y\) that is explained by performing the regression on \(x\).
In the advertising example sales ~ TV, the \(R^2\) is 0.612.
It can be interpreted as 61.2% of the variability in the sales can be explained by a regression on the TV budget.
Notes
If a model is very accurate, the RSS will be much smaller when compared to TSS, which means the \(R^2\) will be close to 1.
The definition of \(R^2\) does not rely on any specific form of the model. In fact, it can be computed for any model with the output \(\hat{y}_i\).
For an OLS regression model, it can be proved that \(0 \leq R^2 \leq 1\).
Generally, \(R^2 \geq 0\) does not hold. Think of an arbitrarily “bad” model.
Predictions: Confidence and prediction intervals
Once we fit a regression model to the data, we can use the model to make predictions. For example, the model predicts that the sales would be 15,000 units with a TV budget of $100k. Often times, in addition to predict a single number of the sales, we want to quantify the uncertainty by constructing a interval in which we have high confidence the sales would fall in.
Theorems
Previously, we know the OLS slope estimator \(\hat{B}_1\) can be written as a linear combination of \(Y_i\) and follows a normal distribution.
Now we take a look at the OLS intercept estimator \(\hat{B}_0\).
Below we prove that \(\hat{B}_0\) also follows a normal distribution with the following mean and variance.
The above result shows the OLS intercept estimator \(\hat{B}_0\) is also unbiased.
In the above proof, we used the fact that \(\text{cov}\big(\bar{Y}, \hat{B}_1\big)=0\). Below is its proof.
Confidence interval
Previously, we compute the model prediction at a given \(x=x^*\) using the formula below.
If we describe the above as a general method of estimating \(y\) at a given \(x=x^*\), we have the estimator for the mean response \(\hat{Y}_{\text{mean}, x=x^*}\), or simply \(\hat{Y}_{\text{mean}}\) as follows.
Let’s construct a confidence interval for \(\hat{Y}_{\text{mean}}\), the mean response for all observations at \(x=x^*\).
The expected value of \(\hat{Y}_{\text{mean}}\):
The variance of \(\hat{Y}_{\text{mean}}\):
The standard error of \(\hat{Y}_{\text{mean}}\):
After replacing \(\sigma\) with RSE, the standardized version of \(\hat{Y}_{\text{mean}}\) follow a t-distribution with a degree of freedom of \(n-2\).
Using similar approach on constructing the confidence interval, we have the confidence interval (with confidence level \(1-\alpha\)) for the mean response at \(x=x^*\):
Note
A confidence interval is used to quantify the uncertainty surrounding the mean response over a large number of observations, all at \(x=x^*\).
The confidence interval for the mean response (\(\hat{Y}_{\text{mean}} = \hat{B}_0 + \hat{B}_1 x^*\)) captures the uncertainty when we estimate the model parameters (\(\beta_0 \text{ and } \beta_1\)) based on data.
Prediction interval
We use a prediction interval to quantify the uncertainty surrounding the response for a single observation at \(x=x^*\).
The simple linear regression model takes the form:
For a single observation the estimator of the response:
Let’s construct a confidence interval for \(\hat{Y}\), the response for a single observation at \(x=x^*\).
The expected value of \(\hat{Y}\):
We see that \(\hat{Y}\) and \(\hat{Y}_{\text{mean}}\) have the same expected value of \(\beta_0 + \beta_1 x^*\), which is the true regression line’s response at \(x=x^*\).
The variance of \(\hat{Y}\):
We see that the variance of \(\hat{Y}\) is larger than the variance of \(\hat{Y}_{\text{mean}}\) by \(\sigma^2\).
The standard error of \(\hat{Y}\):
After replacing \(\sigma\) with RSE, the standardized version of \(\hat{Y}\) follow a t-distribution with a degree of freedom of \(n-2\).
Using similar approach, we have the prediction interval (with confidence level \(1-\alpha\)) for the response to a single observation at \(x=x^*\):
Note
A prediction interval is used to quantify the uncertainty surrounding the response for a single observation at \(x=x^*\).
From the formula we see the prediction interval is always wider than the confidence interval.
The prediction interval (\(\hat{Y} = \hat{B}_0 + \hat{B}_1 x^* + \epsilon\)) not only captures the uncertainty when we estimate the model parameters (\(\beta_0 \text{ and } \beta_1\)), but also the additional uncertainty (\(\epsilon\)) associated with making prediction for a single observation.
Multiple linear regression
Introduction
For the advertising data set, if we want to examine the relationship between all the three media budgets and the sales, we can build three simple linear regression models.
However, a better approach would be to build one linear regression model that incorporating all the three media. We can give each independent variable a separate slope parameter.
This is called a multiple linear regression model, as there are multiple independent variables in the model.
In general, a multiple linear regression model takes the form:
where
\(x_1, x_2, \cdots, x_p\) are \(p\) independent variables;
\(\beta_i\) is the slope parameter associated with independent variable \(x_i\) where \(i=1, 2, \cdots, p\);
\(\beta_0\) is the intercept parameter;
\(\epsilon\) is the same error term in the simple linear regression that followings a normal distribution with a mean of 0 and variance of \(\sigma^2\).
\(Y\) is the dependent variable.
As was the case in the simple linear regression, the model parameters (\(\beta_0, \beta_1, \beta_2, \cdots, \beta_p\)) are unknown and need to be estimated based on data.
We can see \(Y\) is a normally-distributed random variable, as it is a normally-distributed random variable \(\epsilon\) plus some non-random value.
The expected value of \(Y\):
Interpretations of the model parameters
The intercept parameter \(\beta_0\) can be interpreted as the expected value of \(Y\) when \(x_1=x_2=\cdots=x_p=0\).
The slope parameter \(\beta_i\) can be interpreted as the expected change of \(Y\) per unit change of \(x_i\), holding all other independent variables fixed.
The variance of \(Y\):
In summary, we have
Parameter estimation
Previously for simple linear regression, we used a method called Ordinary Least Squares (OLS) that finds the parameters that minimizes the RSS (residual sum of squares). For multiple linear regression we used the same approach. We choose \(\hat{\beta}_0, \hat{\beta}_1, \cdots, \hat{\beta}_p\) such that the RSS is minimized.
The above minimization problem can be solved using the method Maximum Likelihood Estimate (MLE).
The form of the solution is somewhat complex.
In this course we rely on software packages such as the statsmodels library in Python to compute the solution for us.
Model utility test
With a fitted multiple linear regression model, the first question we may ask is “Is the model useful at all?” We can answer this question by a hypothesis test called model utility test or F-test.
\(\text{H}_0\): The model is not useful at all.
\(\text{H}_a\): The model is at least somewhat useful.
Mathematically, this corresponds to
We compute the F-statistic
The numerator \((\text{TSS}-\text{RSS})/p\) measures the variability that can be explained by the model.
The denominator \(\text{RSS}/(n-p-1)\) measures the variability that can not be explained by the model.
Roughly speaking, if a model is useful, the RSS is small, and the F-statistic is large.
If the null hypothesis \(H_0\) is true, the F-statistic follows a F-distribution with degrees of freedom of \(p\) and \(n-p-1\). We reject the null hypothesis if the F-statistic is greater than the critical value \(F_{\alpha, p, n-p-1}\). Otherwise, we fail to reject the null hypothesis. Equivalently, we reject the null hypothesis if the p-value is less than the significant level \(\alpha\).
df |
Sum of squares |
Mean squares |
F |
|
|---|---|---|---|---|
Regression |
\(p\) |
\(\text{TSS} - \text{RSS}\) |
\((\text{TSS} - \text{RSS})/p\) |
\(F=\frac{(\text{TSS}-\text{RSS})/p}{\text{RSS}/(n-p-1)}\) |
Residual |
\(n-p-1\) |
\(\text{RSS}=\sum (y_i-\hat{y}_i)^2\) |
\(\text{RSS}/(n-p-1)\) |
\(-\) |
Total |
\(n-1\) |
\(\text{TSS}=\sum (y_i-\bar{y})^2\) |
\(-\) |
\(-\) |
t-test
If a multiple linear regression model passes the Model utility test, and we conclude that the model is at least somewhat useful, naturally, our next question is which subset of the independent variables are useful? We can perform a t-test to examine whether a specific independent variable (let’s call it \(x_j\)) is useful in predicting the dependent variable \(y\).
\(\text{H}_0\): There is no relationship between \(x_j\) and \(y\).
\(\text{H}_a\): There is some relationship between \(x_j\) and \(y\).
Mathematically, this corresponds to
We compute a t-statistic, given by
If there really is no relationship between \(x_j\) and \(y\), the t-statistic will have a t-distribution with the degree of freedom of \(n-p-1\).
We reject the null hypothesis \(\text{H}_0\) if
or
We can also construct a confidence interval for each slope parameter \(\beta_j\):
Equivalently, we can also check if the confidence interval for \(\beta_j\) include 0. If it does, it means the relationship is not significant.
Note the above parts are very similar to the Hypothesis test when we discussed simple linear regression in the earlier sections, with the only exception of the degree of freedom of the t-distribution now being \(n-p-1\). We can also see the simply linear regression as a special case of multiple linear regression where the number of independent variables \(p=1\).
Similar to earlier we skipped the manual calculation of the OLS solution for the slope parameter \(\beta_j\),
We skip the calculation of the \(\text{SE}(\hat{B}_j)\) and rely on software packages such as the statsmodels library in Python to compute the solutions for us.
Accessing model accuracy
For simple linear regression, we can use RSE (residual standard error) as a measure of model accuracy.
For multiple regression model, we can also compute the RSE with an adjustment to the degree of freedom in the above formula.
Again, the formula above for simple linear regression can be seen as a special case of multiple linear regression when the number of independent variables \(p=1\).
Similar to the arguments from the simple linear regression, RSE is an absolute measure of the model’s lack of fit. More commonly, we use the \(R^2\) statistic to measure the model’s accuracy.
\(R^2\) measures the proportion of variability in \(y\) that is explained by performing the regression on all the independent variables \(x_1, x_2, \cdots, x_p\).
Previously, we showed that in the advertising example if we build a simple linear regression sales ~ TV, the \(R^2\) is 0.612.
With a multiple linear regression sales ~ TV + radio + newspaper, the \(R^2\) is 0.897, which is an improvement in model accuracy after including the two additional independent variables.
Confidence and prediction intervals
Once we build a multiple linear regression model, how can we use the model to make a prediction? And how accurate is the prediction?
To make a prediction at a particular observation of the \(p\) independent variables (\(x_1 = x_1^*, x_2 = x_2^*, \cdots, x_p = x_p^*\)), we use the following formula based on the OLS solution of the parameter estimates (\(\hat{\beta}_0, \hat{\beta}_1, \hat{\beta}_2, \cdots, \hat{\beta}_p\)).
Similar to our discussion during the simple linear regression, to construct the confidence interval of the mean response we need to study the mean response estimator
Skipping the details, we can show that the confidence interval of the mean is
It is a confidence interval of the mean response for all observations at \(x_1 = x_1^*, x_2 = x_2^*, \cdots, x_p = x_p^*\).
Similarly, we can construct a prediction interval for a single observation at \(x_1 = x_1^*, x_2 = x_2^*, \cdots, x_p = x_p^*\).
The single response estimator
We can show that
And
Skipping the details, we can show that the prediction interval is
It is a confidence interval of the response for a single observation at \(x_1 = x_1^*, x_2 = x_2^*, \cdots, x_p = x_p^*\).
We rely on software packages such as the statsmodels library in Python to compute the confidence and prediction intervals for us.
Interactions
In the previous advertising data example, we can build a multiple linear regression model
After fitting a model based on the data, let’s say we have the fitted model
In the above model, for a 1-unit increase in the TV budget, the effect on the sales is 0.0458. Note this is always the case regardless of the level of the radio budget. Similarly, for a 1-unit increase in radio budget, the effect on the sales is 0.1880, regardless of the level of the TV budget. However, in reality maybe with a higher radio budget, the TV budget can be more effective (i.e., with a steeper slope). In other words, maybe the effectiveness of the TV budget depends on the level of radio budget, or we say there may be “synergy” between the TV and radio budget. In statistics, this “synergy” is called interactions among the independent variables.
We can model the (possible) interaction between the TV and radio budget by introducing an interaction term in the model with its own slope parameter.
In the above model, the terms for TV and radio are called the main effect, and the term for \(\text{TV} \cdot \text{radio}\) is called the interaction effect.
We can show that
In the above model the effect of the TV budget on the sales is no longer constant, but depending on the level of radio budget. We can perform the same t-test to determine if the interaction effect is significant or not.
Categorical predictor
A categorical predictor with two levels
In the customer credit data set there is a variable indicating whether a customer is a student (“Yes”) or not (“No”). Intuitively, this piece of information may be helpful in predicting one’s credit balance. However, unlike all the independent variable we have seen so far, this variable does not take numerical values, but rather, two categories of either “Yes” or “No”. How can we incorporate this categorical variable into a regression model to predict the credit balance?
For a categorical variable that has two categories (e.g., “Yes” and “No”, often referred to as having two “levels”), we can create a dummy variable with values of either 0 (representing “No”) or 1 (representing “Yes”).
Then we include this dummy (binary) variable into the regression model just like we would for any numerical variables.
Then
For non-students (i.e., \(\text{student}=0\)) the regression line becomes
For students (i.e., \(\text{student}=1\)) the regression line becomes
The above shows for both the students and non-students, the income have the same main effect (of \(\beta_1\)) on the balance. The difference is the intercept. For a student and a non-student with the same income, the student’s balance is \(\beta_2\) higher [1] than the non-student. Often the category that is set to 0 in the dummy variable (the non-student in this case) is called the baseline.
A categorical predictor with more than two levels
In the customer credit data set there is a variable indicating a customer’s ethnicity. The variable has three categories (i.e., levels): African American, Asian, and Caucasian.
A natural thought may be to create a dummy variable that encodes the three ethnicity groups with values of 0, 1, and 2.
For example, we can create a dummy variable ethnicity:
Then we include this dummy variable into the regression model just like we would for any numerical variables.
Then
For African American (i.e., \(\text{ethnicity}=0\)) the regression line becomes
For Asian (i.e., \(\text{ethnicity}=1\)) the regression line becomes
For Caucasian (i.e., \(\text{ethnicity}=2\)) the regression line becomes
The above three regression lines have the same slope of \(\beta_1\), but different intercepts of \(\beta_0\), \(\beta_0 + \beta_2\), and \(\beta_0 + 2\beta_2\).
This essentially assigns (1) a particular order of the three ethnicity groups, and (2) equal distance between African American and Asian, and between Asian and Caucasian who have the same income. In reality, there is little reason to believe these assumptions are valid.
For this reason, a better way to include the Ethnicity variable into the model is to create not one, but two dummy (binary) variables.
In this setting we can encode the three ethnicity groups as shown the table below. This method is called One Hot Encoding.
Categories \ Dummy variables |
\(\text{asian}\) |
\(\text{caucasian}\) |
|---|---|---|
Asian |
1 |
0 |
Caucasian |
0 |
1 |
African American |
0 |
0 |
After applying the above encoding, we include the two dummy variable into the regression model.
Then
For African American (i.e., \(\text{asian}=0, \text{caucasian}=0\)) the regression line becomes
For Asian (i.e., \(\text{asian}=1, \text{caucasian}=0\)) the regression line becomes
For Caucasian (i.e., \(\text{asian}=0, \text{caucasian}=1\)) the regression line becomes
The above three regression lines have the same slope of \(\beta_1\), but different intercepts of \(\beta_0\), \(\beta_0 + \beta_2\), and \(\beta_0 + \beta_3\). For the customers who have the same income, the distance between the African American (baseline) and Asian is \(\beta_2\), and the distance between the African American (baseline) and Caucasian is \(\beta_3\). This allows us to model these distances (which are likely different in reality) using two separate parameters.
In general, we need to create one fewer dummy binary variables than the number of levels in the categorical predictor.
Similar to our discussion earlier on the interaction between the income and student, we can further add the interaction effect to model the different income slopes for different ethnicity groups.
Footnotes
Non-linear relationship
Question: Is the model below a linear regression model?
Let \(x_1=x, x_2=x^2\), we have
After the transformation the model become a linear regression model. If this is the case, we say the original model is intrinsically linear.
Note
The word “linear” in linear regression model does not mean the independent variables are linear. Rather, it means the regression coefficients (\(\beta_0, \beta_1, \beta_2\), etc.) are linear.
Question: Are the models below a linear regression model?
Answer: They are not, as the regression coefficients are not linear.
Examples of other intrinsically linear models:
Example 1:
Let \(x_1=\sin x, x_2=\cos x\), we have
As we can see, the model become linear regression model after the transformation, thus it is intrinsically linear.
Example 2:
Take natural logarithm on both side of the equation, we have
Let \(y'=\ln Y, \beta_0 = \ln \alpha, x'=x^2\), we have
As we can see, the model become linear regression model after the transformation, thus it is intrinsically linear.
Polynomial regression
A polynomial regression model (with order \(p\)) takes the following form
Model evaluation metrics
Loosely speaking, we evaluate a model by looking at the average amount of errors that it makes. The error at the \(i\)-th observation \(e_i\) is computed as the difference between the true value of the dependent variable \(y_i\) and the model predicted value \(\hat{y}_i\).
We discussed earlier that when constructing a model performance metric, it is not a good idea to simply sum up the errors, as the positive errors and negative errors will cancel each other out. This may give us a model that have very small overall errors, and yet has large positive and negative errors. Commonly, we want to convert the negative errors to positive before summing them up.
A simple way is to take the absolute value of all errors before summing them up.
Another common way is to square the errors before summing them up.
Note because of the square operation, MSE effectively gives a heavier weight on the observations with large errors. This may or may not be a desired property depending on the applications.
A practical drawback of MSE is that it has a unit of the square of the unit of the dependent variable \(y\). For example, if the dependent variable \(y\) is house prices measured in dollars, the MSE will have the unit of dollars-squared, which may not be easy for one to directly understand and interpret. A simple solution is to take a square root of the MSE, and get the Root Mean Squared Error (RMSE), which shares the same unit as the dependent variable \(y\).
As we discussed before, another commonly used metric to evaluate a model is \(R^2\), which measures the proportion of variability in the dependent variable \(y\) that can be explained by the model.
Overfitting
Overfitting refers to a situation in which the model follows too closely to the data. In other words, the model is working too hard to find patterns in the data, and as a result, it may be picking up things that are just caused by noise, rather than the real underlying patterns. Overfitting is undesirable because the fitted model will yield worse results with new data.
One limitation of using \(R^2\) as a model evaluation metric is that it does not detect overfitting of a model. As a model becomes more complex, a possibly overfitted model with many parameters may actually result in a better metric (i.e., higher \(R^2\)). For this reason, the adjusted \(R^2\) is often used instead.
where \(p\) is the number of predictors.
Essentially, in the adjusted \(R^2\), both the RSS and TSS are divided by their corresponding degrees of freedom. This effectively penalize a more complex model with large number of parameters \(p\).
In some cases if we already know a model’s \(R^2\), we can compute the adjusted \(R^2\) from the \(R^2\). We replace \(\frac{\text{RSS}}{\text{TSS}}\) in the first equation above with \(1-R^2\). Then we have:
Train/test split
An alternative approach to evaluate the models is to split the data into two parts:
a training set
a test set
Then we build the model using only the training set, and evaluate the model performance using only the test set.
Advantages over using the adjusted \(R^2\)
More straightforward, provides a direct estimate of the test error.
Disadvantages
More computationally expensive (less of an issue nowadays)
Train/test split may have high variance.
Cross-validation
Cross-validation is a common method to combat the high variance of the train/test split method.
Procedure of conducting a (k-fold) cross-validation
The training set is split into \(k\) groups, or folds, of approximately equal size.
A model is trained using \((k-1)\) of the folds as training data.
The resulting model is validated on the remaining fold. This fold is often called “held out validation set”.
The performance measure reported by the k-fold cross-validation is the average of the values.
To use cross-validation we can use the scikit-learn cross_val_score function.
Further resources
Logistic regression
Will a credit card customer default?
import pandas as pd
df = pd.read_csv('./data/default.csv')
df.head()

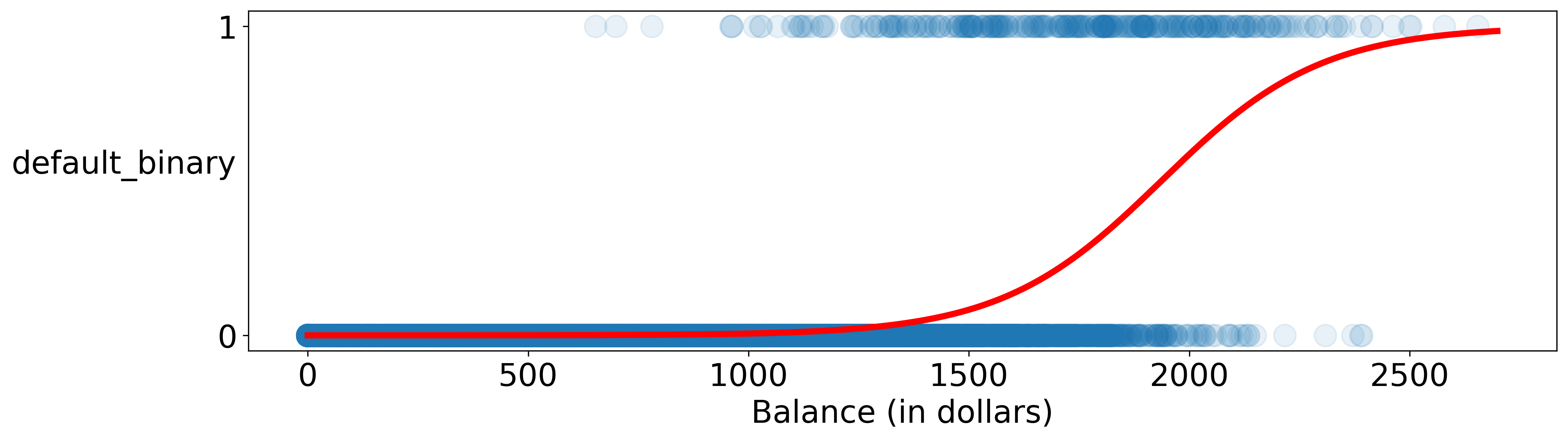
We can create a dummy binary variable to indicate whether a customer will default or not.
Let’s make a scatter plot to examine the relationship between the binary variable for default and customers’ credit balance.
plt.scatter(x='balance', y='default_binary', data=df)

Where \(p(x)\) is probability that a customer with a credit balance of \(x\) will default.
We can rearrange the above equation by doing the following
In statistics \(\frac{p(x)}{1-p(x)}\) is often referred to as the odds. It is the ratio of the probability that an event will occur to the probability that the event will not occur. We can see from above that the natural log of the odds, often called the log-odds or logit, is a linear function of \(x\).
Interpretation of the slope parameter \(\beta_1\).
When we increase \(x\) by one unit, the odds
increase by a ratio of \(e^{\beta_1}\).
If we take natural log to both side of the equation above,
This gives another way to interpret the slope parameter: When we increase \(x\) by one unit, the log-odds
increase by \(\beta_1\).